
EigenCAM for YOLO5
EigenCAM for YOLO5#

In this tutorial we’re going to see how to use EigenCAM (one of the gradient free methods) for YOLO5.
This is a much simpler version of the tutorial in https://github.com/jacobgil/pytorch-grad-cam/blob/master/tutorials/Class Activation Maps for Object Detection With Faster RCNN.ipynb adapted for YOLO5.
If you wanted to use other methods like AblationCAM, you can use the other tutorial.
As a reminder from the tutorial above, we’re going to use gradient free methods for object detection, since most frameworks won’t support computing gradients.
We’re going to use the YOLO5 model from ultralytics
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)`
As you recall, when adapting this library to new architectures, there are three main things you need to think about:
The reshape transform. This is used to get the activations from the model and process them so they are in 2D format. Sometimes the layers will not output tensors, for example, but tuples of tensors. So we need a function that knows to dig into the output and find our 2D activation.
In the case of YOLO5, no need for this, we’re getting a 2D spatial tensor.
The target function that guides our class activation map.
In the case of EigenCAM, there is no target function. We’re going to do PCA on the 2D activations.
If we would use another method like AblationCAM we would need this, and then you can look at the faster-rcnn tutorial above.
The target layer to extract the 2D activations from. We’re going to use the second last layer. The last layer in YOLO5 outputs the detections, so instead we’re going to use the one before it. After printing the model and playing with it, this is in
model.model.model.model[-2]
First lets write some boiler plate code for doing a forward pass on the image, and displaying the detections:
import warnings
warnings.filterwarnings('ignore')
warnings.simplefilter('ignore')
import torch
import cv2
import numpy as np
import requests
import torchvision.transforms as transforms
from pytorch_grad_cam import EigenCAM
from pytorch_grad_cam.utils.image import show_cam_on_image, scale_cam_image
from PIL import Image
COLORS = np.random.uniform(0, 255, size=(80, 3))
def parse_detections(results):
detections = results.pandas().xyxy[0]
detections = detections.to_dict()
boxes, colors, names = [], [], []
for i in range(len(detections["xmin"])):
confidence = detections["confidence"][i]
if confidence < 0.2:
continue
xmin = int(detections["xmin"][i])
ymin = int(detections["ymin"][i])
xmax = int(detections["xmax"][i])
ymax = int(detections["ymax"][i])
name = detections["name"][i]
category = int(detections["class"][i])
color = COLORS[category]
boxes.append((xmin, ymin, xmax, ymax))
colors.append(color)
names.append(name)
return boxes, colors, names
def draw_detections(boxes, colors, names, img):
for box, color, name in zip(boxes, colors, names):
xmin, ymin, xmax, ymax = box
cv2.rectangle(
img,
(xmin, ymin),
(xmax, ymax),
color,
2)
cv2.putText(img, name, (xmin, ymin - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.8, color, 2,
lineType=cv2.LINE_AA)
return img
image_url = "https://upload.wikimedia.org/wikipedia/commons/f/f1/Puppies_%284984818141%29.jpg"
img = np.array(Image.open(requests.get(image_url, stream=True).raw))
img = cv2.resize(img, (640, 640))
rgb_img = img.copy()
img = np.float32(img) / 255
transform = transforms.ToTensor()
tensor = transform(img).unsqueeze(0)
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', pretrained=True)
model.eval()
model.cpu()
target_layers = [model.model.model.model[-2]]
results = model([rgb_img])
boxes, colors, names = parse_detections(results)
detections = draw_detections(boxes, colors, names, rgb_img.copy())
Image.fromarray(detections)
Using cache found in C:\Users\Jacob Gildenblat/.cache\torch\hub\ultralytics_yolov5_master
YOLOv5 2022-4-1 torch 1.10.1+cu102 CUDA:0 (Quadro RTX 5000, 16384MiB)
Downloading https://github.com/ultralytics/yolov5/releases/download/v6.1/yolov5s.pt to yolov5s.pt...
Fusing layers...
YOLOv5s summary: 213 layers, 7225885 parameters, 0 gradients, 16.5 GFLOPs
Adding AutoShape...

Now lets create our CAM model and run it on the image:
cam = EigenCAM(model, target_layers, use_cuda=False)
grayscale_cam = cam(tensor)[0, :, :]
cam_image = show_cam_on_image(img, grayscale_cam, use_rgb=True)
Image.fromarray(cam_image)
(1, 512, 20, 20)

This contains heatmaps mainly on the dogs, but not only.
Something we can do for object detection is remove heatmap data outside of the bounding boxes, and scale the heatmaps inside every bounding box.
def renormalize_cam_in_bounding_boxes(boxes, colors, names, image_float_np, grayscale_cam):
"""Normalize the CAM to be in the range [0, 1]
inside every bounding boxes, and zero outside of the bounding boxes. """
renormalized_cam = np.zeros(grayscale_cam.shape, dtype=np.float32)
for x1, y1, x2, y2 in boxes:
renormalized_cam[y1:y2, x1:x2] = scale_cam_image(grayscale_cam[y1:y2, x1:x2].copy())
renormalized_cam = scale_cam_image(renormalized_cam)
eigencam_image_renormalized = show_cam_on_image(image_float_np, renormalized_cam, use_rgb=True)
image_with_bounding_boxes = draw_detections(boxes, colors, names, eigencam_image_renormalized)
return image_with_bounding_boxes
renormalized_cam_image = renormalize_cam_in_bounding_boxes(boxes, colors, names, img, grayscale_cam)
Image.fromarray(renormalized_cam_image)
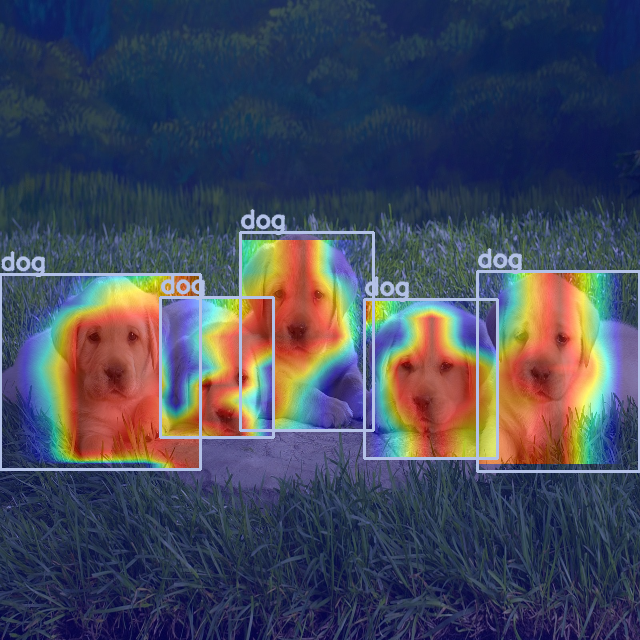
Image.fromarray(np.hstack((rgb_img, cam_image, renormalized_cam_image)))
