Here is the github repository with all the code for this post.
Scroll to the end if you just want to see images.
In this post I will describe two experiments I did with Dlib’s deep learning face detector:
- Porting the model weights to PyTorch, and testing it by detecting faces in a web cam feed.
- Hallucinating faces using Activation Maximization on the model filters.
Dlib’s deep learning face detector is one of the most popular open source face detectors. It is used in many open source projects like the open face project, but also in countless industry applications as well. It is trained with the clever max margin object detection agorithm that penalizes objects that are not exactly in the center of the scanning window, thus learning non maximum supression, giving very accurate localization.
This is a good place to say that DLib is a remarkable piece of software, and it’s creator Davis King is one of the heros of the internet.
At this point Dlib only has support for converting the model weights to caffe, so I decided to jump in and add support for converting the face detector model to PyTorch. From PyTorch it can be easily be ported to many other platforms with the ONNX format, so getting dlib’s face detector to work in mobile deep learning frameworks should be straight forward from here.
Converting the model to PyTorch
The first part here was saving the face detector model in an XML format, using net_to_xml, like in this dlib example.
The XML is fairly easy to parse in python, with each layer’s parameters (like the layer type, padding, kernel size etc) stored in XML attributes, followed by a list of floats for each layer’s biases and weights.
Batch normalization is implemented a bit differently in DLib, without a running mean and running variance as part of the layer parameters, so a running mean and variance of 0 and 1 is used in PyTorch.
get_model gets the XML path, and returns a PyTorch Sequential model.
Verifying it by detecting faces in a webcam
The purpose of this section was to make sure the ported model is usable. You can skip to the next section for the face hallucinations.
On a i7 processor, the inference took between 30ms to 150ms on a 640x480 feed from a webcam, depending on the scales used, which isn’t bad at all. Running it on higher end mobile devices (after porting to ONNX) should give a much faster inference time.
Dlib’s face detector is a fully convolutional network, that slides over an input image and outputs a score for each window in the image. The network is aimed at detecting faces that have a certain size, determined by the receptive field of the network.
To get scale invariance, Dlib resizes the input images to different sizes, and packs them in a single image with paddings between the scaled images. This trades off more inference time with scale invariance. Inference on the packed larger image gives larger GPU utilization. Since I was doing this on a CPU, I didn’t really have a motivation for doing the image packing, so instead I just did multiple forward passes on resized images.
After detection, non maxima suppression is done between the different scales, and the box size is receptive field is multiplied by the scale that best detected the object.
Here is the code for face detection on a webcam.
Hallucinating faces
Now that we have the PyTorch model, we can use activation maximization to find images that cause a large response in specific filters. The idea is to perform gradient ascent iterations on the input image pixels, until a large activation in filter output is caused.
I tried a lot of things until I managed to get this to work. Here is a short summary of some of the things I used:
- The loss function is the center pixel in the filter output. Usually when using activation maximization, the mean output of the filter is used as the loss function. To get face images, instead I used the center pixel in the output of the filter. This is probably related to how the model was trained - if a face is centered in the middle of the window, its score will be highest.
- Regularization: Without regularization, the images look extremely noisy. The regularization that worked best here was rotating the image by a random angle (I used a range of [-30, 30]), calculating the image gradients, and then rotating back. A random horizontal flip also seemed to help. Initially I tried using bilateral filtering on the gradients, and decaying the image by 0.95, but those didn’t really help and the results weren’t as nice.
-
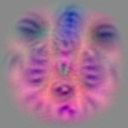
Peeking at the second last convolutional layer. The output from the last convolutional layer used a combination of the outputs in the one before, and tends to return multiple faces (often in different poses) in the same image. This kind of makes sense, since there are many different types of faces that can all cause a face to be detected.
On the other hand, maximizing the second last convolutional layer responses returns single faces, probably because they learned to be much more selective in the kind of faces they respond to. Different runs on the same filter often returns different poses and expressions, of the same face.
- Solving instead for a low activation, often still returns faces, but they aren’t in the center of the image. This kind of makes sense because the face detector is trained to give a low response if the face has an offset to the window center, treating it as a false positive. So many of the “negative” responses have meanings - They aren’t just random background patterns, they are faces, and face parts, in different areas of the image.
Images that maximize the activation
These are selected filters. Some filters did not correspond to faces, or had multiple faces. For each filter, there were 900 iterations of gradient ascent, repeated 10 times to create 10 different images.





























































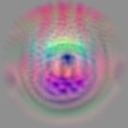






































































































Images that minimize the activation